
激光SLAM学习
IMU

运动学
噪声运动模型

- 测量噪声:是 “零均值白高斯噪声”—— 干扰是随机的、没有固定偏向,而且不同时刻的干扰互不影响。可以用 “高斯过程” 描述,方便从连续时间(比如实时测量)推导到离散时间(比如每隔 0.1 秒采样一次)的噪声。
- 零偏(固有偏差):是 “随机游走”(类似 “布朗运动”)—— 零偏会从初始值开始,随机地慢慢 “飘移”。比如加速度计的零偏ba,它的变化率(飘移的快慢)也是一种高斯噪声;陀螺仪的零偏bg同理。
陀螺仪和加速度的离散噪声模型

- 测量噪声,在整个运动模型看来是角度随机游走和速度随机游走。
- 零偏随机游走方差,手册里经常给出的是零偏重复性和运行时偏置稳定性来代替。
航迹推算
测量模型代入运动学方程
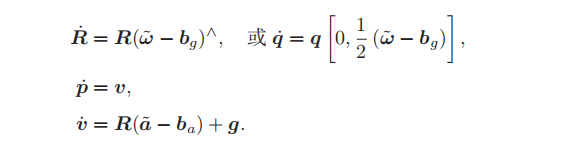
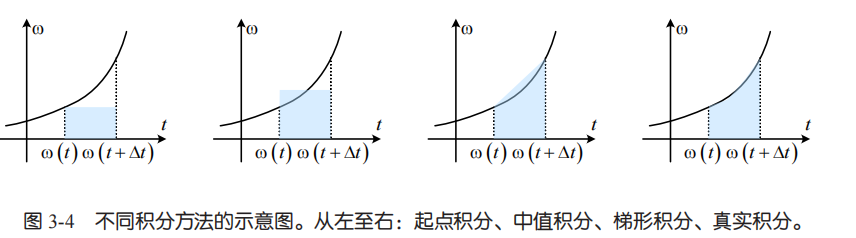
积分
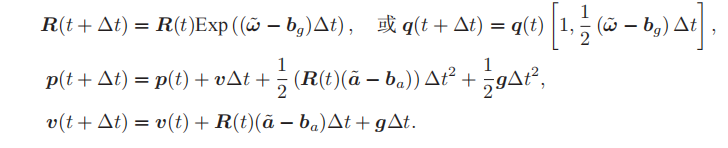
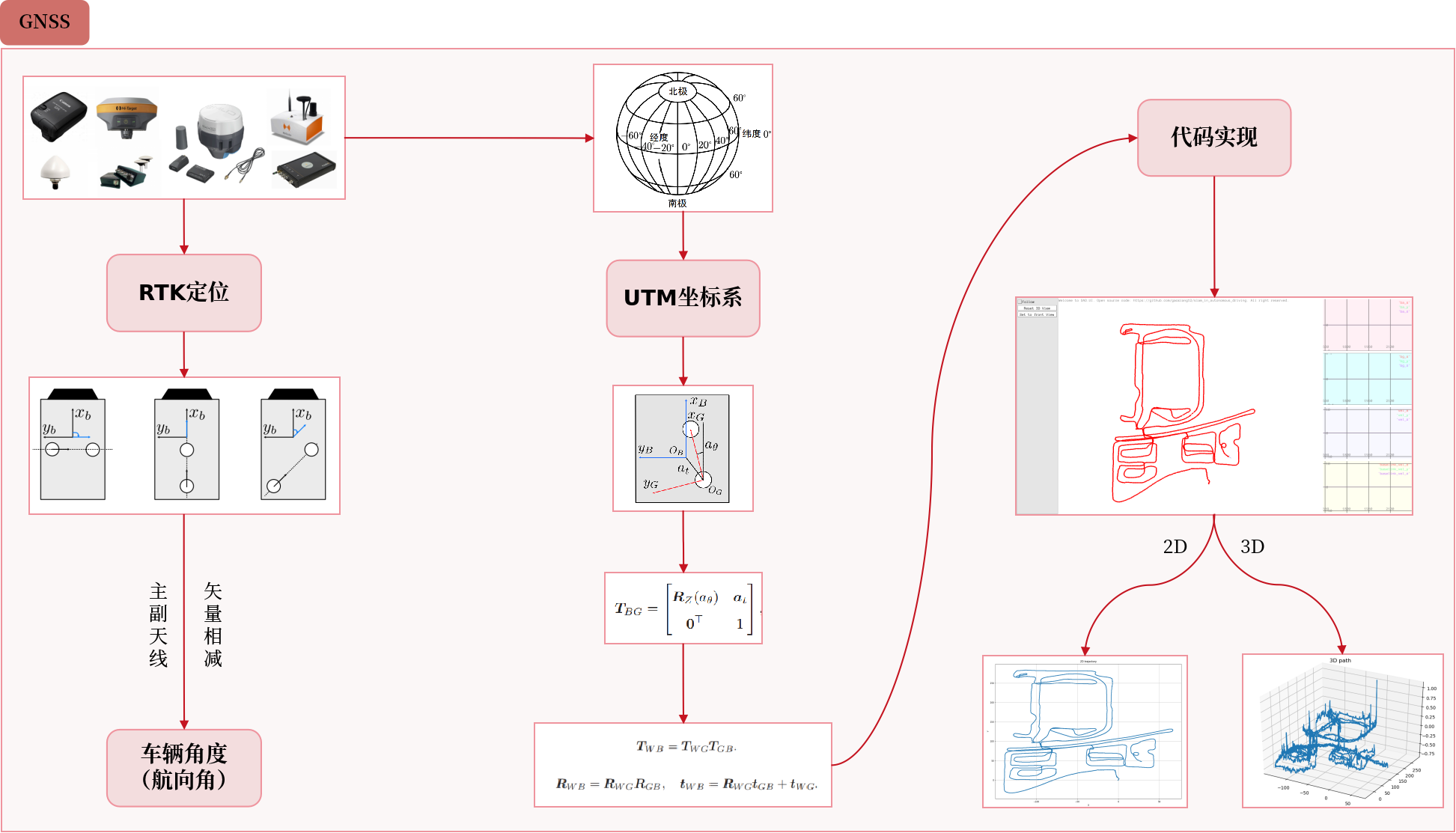
GNSS
ESKF
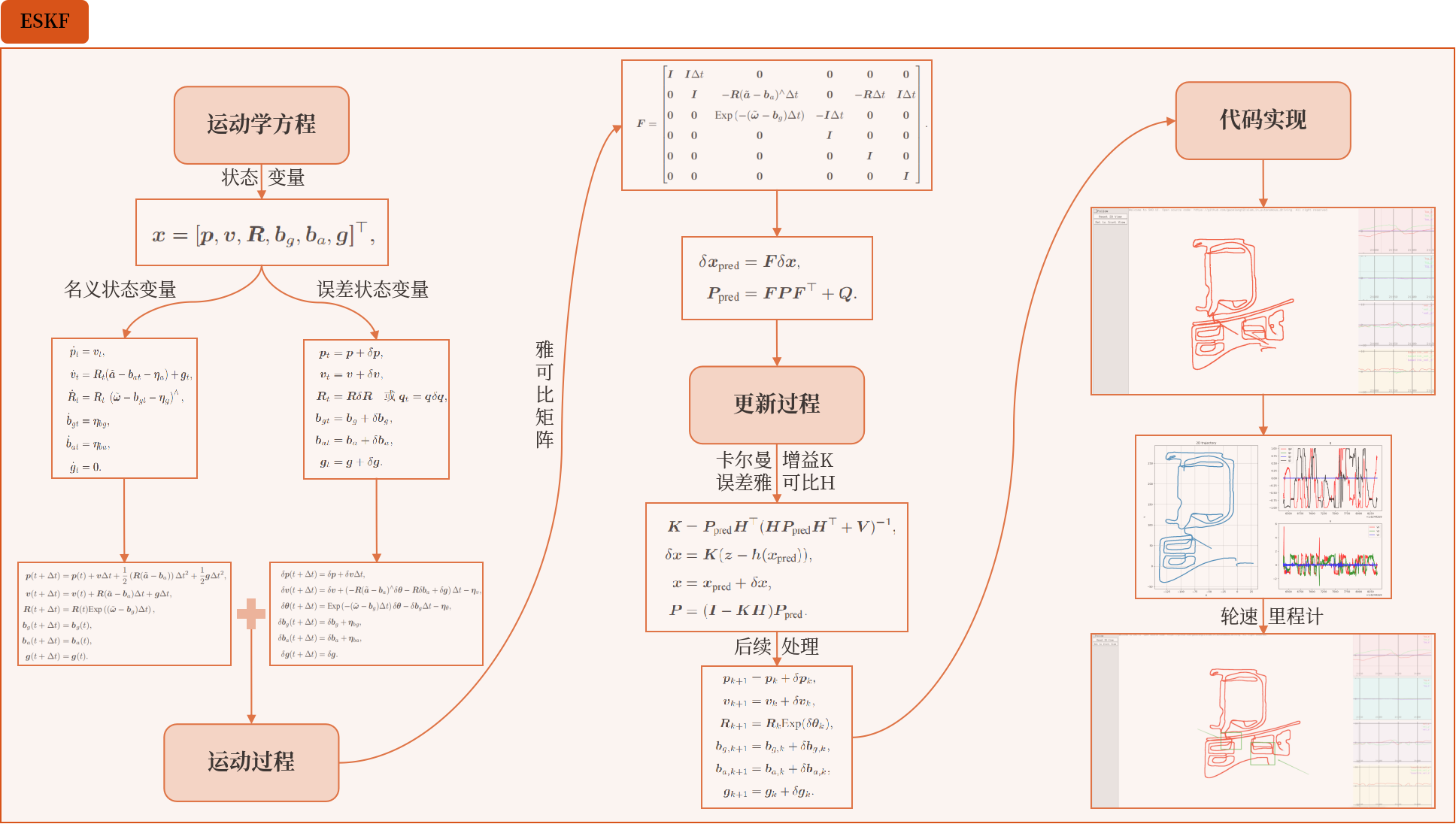
雅可比矩阵
核心作用:描述 “输入微小变化” 如何影响 “输出的每一个维度”,是向量函数的 “一阶导数”。偏导数
海森矩阵
核心作用:描述函数的局部曲率(弯曲程度),是标量函数的 “二阶导数”。向量函数的二阶导数是多个海森矩阵组成的张量 / 分块结构。
协方差
总体协方差
样本协方差
协方差矩阵
相关系数
方差计算
在机器人、导航等领域,卡尔曼滤波用协方差矩阵描述 “状态不确定性” 的传播:
- 每次传感器测量后,协方差矩阵更新 “当前状态的置信度”;
- 协方差越小,说明状态估计越准确。
协方差只能衡量线性关系,对非线性关系无能为力。
名义状态变量
当 IMU(惯性测量传感器)数据到来时,先 “不考虑噪声”,直接把数据积分到名义状态里(相当于按 “理想无干扰” 的情况推算位置、姿态)。运动过程中,名义状态靠 IMU 数据持续推算;
误差状态变量
现实有噪声(比如传感器误差、外界干扰),所以名义状态会慢慢 “跑偏”,这时候误差状态就记录 “跑偏的程度”。误差状态会因噪声影响越来越大,ESKF 能用 “均值 + 协方差”(类似 “统计描述误差有多大、多分散”)来刻画误差的扩大。
推导过程
第一步:明确“状态拆分”逻辑
把真实状态(比如机器人的实际位置、速度、旋转等)拆成两部分:
名义状态(不带下标,如( $\boldsymbol{p}$ )、( $\boldsymbol{v}$ )、( $\boldsymbol{R} $)):“理想的、无噪声的状态”(类比:导航告诉你“应该在的位置”)。
误差状态(如( $\delta \boldsymbol{p}$ )、( $\delta \boldsymbol{v}$ )、($ \delta \boldsymbol{R} $)):“真实状态与名义状态的偏差”(类比:你实际位置和“应该位置”的差距)。
所以真实状态 = 名义状态 + 误差状态
第二步:处理“旋转”的非线性
李群&李代数旋转(比如旋转矩阵( $\boldsymbol{R}$ ))属于李群(( SO(3) ))——它的运算(矩阵乘法)是非线性的,直接处理“旋转误差”很麻烦。
这时候用李代数($ \mathfrak{so}(3)$ :李代数是“旋转的微小增量(三维向量( $\delta \boldsymbol{\theta} $)”,是线性空间(可以像普通向量一样做加减、数乘)。通过“指数映射”$ \text{Exp}(\delta \boldsymbol{\theta}) $,能把“李代数(三维向量)”转换成“李群(旋转矩阵( $\delta \boldsymbol{R}$)”。 通俗说:旋转的“大变化”是非线性的,但“微小偏差”可以用“线性的三维向量”描述,再通过“指数映射”转换成旋转矩阵的偏差。这样就把旋转的“非线性误差”变成了“线性的李代数向量”,方便后续计算。
真实旋转矩阵可表示为「名义旋转矩阵 R」与「误差旋转的指数映射 Exp(δθ)」的乘积:
两侧求导:
指数映射 Exp(δθ) 对时间的导数满足李群微分规则($\dot R=\dot{\text{Exp}}(\phi^\wedge)\dot \phi^\wedge$):
代入
由于式 (3.30) 和 (3.31) 左边都是 R˙t,因此右边相等。两边左乘 R−1(因 R 是正交矩阵,R−1=R⊤),消去 R 后整理得:
旋转矩阵群 SO(3) 满足伴随性质:对任意 R∈SO(3) 和向量 ϕ,有
其中≈处使用一阶泰勒展开
最终误差角速度方程
第三步:对“真实运动方程”线性化
真实状态的运动是非线性的(比如旋转的乘法、加速度受旋转的变换等),但因为“误差状态是小量”,所以可以用泰勒一阶展开(线性化)——把复杂的非线性关系,在“名义状态附近的小范围”近似成“直线关系”(线性关系),忽略高阶小量。 以“位置和速度”为例:
- 真实位置的导数是真实速度:($ \dot{\boldsymbol{p}}_t = \boldsymbol{v}_t $)
- 代入“真实=名义+误差”:( $\dot{\boldsymbol{p}} + \delta \dot{\boldsymbol{p}} = \boldsymbol{v} + \delta \boldsymbol{v}$ )
- 名义状态的导数是名义速度:( $\dot{\boldsymbol{p}} = \boldsymbol{v} $)
- 所以化简得:( $\delta \dot{\boldsymbol{p}} = \delta \boldsymbol{v}$ )(位置误差的变化率=速度误差)
再以“速度和加速度”为例(加速度受旋转、重力、传感器偏置影响): 真实加速度的计算涉及“旋转矩阵对加速度的变换”“偏置的影响”“重力的影响”。把这些“真实项”用“名义+误差”展开,再因为“误差是小量”,忽略高阶项,最终能得到速度误差的线性微分方程(形式为“速度误差的变化率 = 雅克比矩阵×误差 + 噪声”,雅克比是线性化的系数)。
第四步:推导各误差状态的微分方程
对位置、速度、旋转(李代数形式)、传感器偏置、重力等,逐一重复“线性化真实运动方程”的过程,最终得到所有误差状态的变化率(导数)与误差自身、输入噪声的线性关系,这就是误差状态方程。 比如:
- 传感器偏置的误差(如陀螺仪偏置( $\delta \boldsymbol{b}_g$ )),通常假设“偏置缓慢变化”,其误差方程可能是“($ \delta \dot{\boldsymbol{b}}_g = \text{随机噪声}$ )”(简化模型)。
- 重力的误差,若局部区域重力变化小,也可做简化假设(如误差变化率为0)。
把误差变量的运动学方程整理如下:
核心原理总结
ESKF推导的核心是“化繁为简”:
- 把“难处理的真实状态”拆成“好算的名义状态 + 小量的误差状态”;
- 对“非线性的旋转”,用“李代数(线性小向量)+ 指数映射”把非线性误差转成线性;
- 因为“误差是小量”,把所有非线性运动方程近似成线性方程(泰勒一阶展开);
- 最终得到“误差如何随时间变化”的线性方程,方便用卡尔曼滤波估计误差,再修正名义状态。 类比:就像用“粗略地图(名义状态)+ 小范围偏差(误差状态)”导航,因为偏差小,所以“偏差的变化”可以用简单的线性规律计算,最后把偏差补到粗略地图上,就能得到精准位置。
ESKF预测过程
预测分为名义状态预测和误差状态预测:
名义状态预测:直接用 IMU 原始数据(角速度 ω~、加速度 a~)积分,得到 “无误差的粗略状态”(这是传统惯性导航的积分过程,不涉及滤波,仅更新 “名义值” 的大趋势)。
误差状态预测:
- 误差状态先验:利用线性化的离散方程 $δx_{pred}=Fδx$,即 “当前误差状态乘以雅克比矩阵 F,得到预测时刻的误差状态”(因误差是小量,线性关系成立)。
- 误差协方差先验:利用线性卡尔曼滤波的协方差传播律 $P_{pred}=FPF^⊤+Q$,其中 P 是当前误差协方差,Q 是过程噪声协方差(由各误差项的噪声方差组成)。
ESKF 推导的核心是分而治之:
对 “大状态(名义状态)” 用非线性积分(惯性导航)保证趋势;
对 “小偏差(误差状态)” 用线性化 + 线性卡尔曼滤波处理精度;
:exclamation:为什么预测误差协方差:grey_question:
答:在误差状态卡尔曼滤波器(ESKF)中,预测误差协方差是为了跟踪误差的不确定性如何随系统运动和噪声传播,是卡尔曼滤波 “最优融合预测与观测” 的核心前提。卡尔曼滤波分 “预测(Predict)” 和 “更新(Update)” 两步。
名义状态变量的离散时间运动学方程:
误差状态变量的离散时间运动学方程:
ESKF更新过程
ESKF的误差状态后续处理
ESKF(误差状态卡尔曼滤波器)完成 “预测 - 更新” 后,要做两件事:把误差 “合并” 到名义状态,再重置滤波器,方便下一轮迭代。
名义状态是 “当前认为的大致状态”,误差是 “修正量”。需要把修正量合并到名义状态里,得到更准确的状态:
- 位置、速度、陀螺偏置、加速度计偏置、重力:直接用「名义值 + 误差值」(比如新位置 = 旧名义位置 + 位置误差)。
- 旋转(特殊情况):旋转不能直接 “相加”,得用指数映射(把旋转误差从 “线性的小量描述” 转换成 “旋转矩阵的形式”),再和旧的旋转矩阵相乘(公式里 Rk+1=RkExp(δθk),就是旧旋转 “叠加” 误差对应的旋转)。
合并完误差后,要重置滤波器,让它能继续处理下一段时间的误差:
- 均值部分:把误差状态 δx 置为 0。因为误差已经 “合并到名义状态里了”,现在误差状态要重新开始跟踪新的误差,所以均值归零。
- 协方差部分:重置后,协方差的 “参考基准” 变了。尤其是旋转,它的 “线性近似空间(切空间)” 的 “零点” 发生了变化,所以数学上要区分 “重置前 和 “重置后的协方差。
代码实现
参数初始化
1 | template <typename S = double> |
名义状态包含位置、速度、旋转、零偏和重力,误差状态对应它们的向量形式。误差状态变量应该为 3 × 6 = 18 维向量,对应的协方差矩阵亦为 18 × 18 维方阵。
预测过程
1 | template <typename S> |
RTK预测
RTK 既能观测位置,也能观测角度(单天线不可)。
1 | bool ESKF<S>::ObserveGps(const GNSS& gnss) { |
SE3观测处理函数,用GNSS的UTM位姿修正滤波器状态
1 | template <typename S> |
将误差状态融合到名义状态中,并重置误差状态
1 | /// 更新名义状态变量,重置error state |
静止初始化
在静止时间内,由于物体本身没有任何运动,可以简单地认为 IMU 的陀螺仪只测到零偏,而加速度计则测到零偏与重力之和。
- 让车辆静止:程序设 10 秒,用轮速判断(两轮速度都低于阈值就算静止;没轮速时,直接假设车辆静止)。
- 统计传感器平均读数:记录这 10 秒内陀螺仪、加速度计的读数平均值,分别叫dˉgyr、dˉacc。
- 确定陀螺仪零偏:车辆没转动,所以陀螺仪的 “静止偏差(零偏)bg” 就等于陀螺仪的平均读数dˉgyr。
- 确定重力方向:加速度计的测量公式里,车辆静止时实际加速度为 0、旋转近似为 “无旋转”(旋转矩阵R看成单位阵),此时加速度计测的是 “加速度计偏差ba-重力g”。于是,取 “加速度计平均读数的反方向”、大小 9.8 的向量,作为重力g的方向。
- 去除重力重算加速度计平均:把加速度计读数里的重力成分去掉,重新计算加速度计的平均值dˉacc。
- 确定加速度计零偏:加速度计的 “静止偏差(零偏)ba” 等于重新计算后的加速度计平均值dˉacc。
- 估计测量方差:假设零偏不变,算出陀螺仪、加速度计的测量方差,这些方差能作为 ESKF(误差状态卡尔曼滤波器)的噪声参数,让后续滤波更准确。
运行
ERROR:
1 | ./bin/run_eskf_gins: error while loading shared libraries: libpango_windowing.so.0: cannot open shared object file: No such file or directory |
解决:
1 | sudo ldconfig |
基础融合:IMU+GNSS 的优势
IMU(惯性测量单元)的优点是 “更新快”(高频定位),但单独用会慢慢飘(误差累积);GNSS(卫星定位)的优点是 “准且稳”,但更新慢。ESKF 把两者融合后,既能输出高频定位信号,又能让精度和 GNSS 差不多,兼顾了 “快” 和 “稳”。
不止 IMU+GNSS,其他传感器也能融
比如后续要加的激光雷达、摄像头,只要能把它们的观测数据 “转化成 ESKF 能处理的线性形式”(专业叫 “线性化”),就能融入 ESKF。比如激光先算出自家的位姿,再给 ESKF;摄像头先算特征点的位置误差,再给 ESKF—— 核心理论都一样,只是不同传感器的 “噪声大小 / 规律” 不一样(比如激光噪声可能比摄像头小)。
两种融合方式:松耦合 vs 紧耦合
- 松耦合(简单直接):融的是 “传感器先算好的位姿结果”(比如激光先自己算出车辆位姿,再把这个位姿当 “观测值” 给 ESKF),不用管传感器原始数据。
- 紧耦合(更精细):不融 “算好的位姿”,直接融 “传感器的原始误差”(比如激光点云跟地图匹配的偏差、摄像头特征点投到图像上的位置误差),更直接利用原始数据,精度通常更高。
对比下 ESKF 和图优化在处理 “运动状态”(比如位置、速度)和 “传感器观测数据”(比如 GNSS、轮速)时的思路:两者很多核心逻辑是相通的,但具体动手做的
方式不一样。
这里要重点说 ESKF 的一个关键操作:它的 “更新过程” 本质是在做 “边缘化”。简单理解就是,ESKF 会把过去所有传感器的观测信息(比如之前的 GNSS 数据、轮
速数据)“打包压缩”,变成一份 “参考依据”(专业里叫 “先验”),直接用在当前时刻的计算中。而且 ESKF算出的当前状态均值 x(比如当前位置、速度的估计值)
和方差 P(这个估计值的不确定性),不只是用在当下,还会当成 “提前准备好的参考” 传给下一个时刻。有了这份 “参考”,滤波器每次迭代更新时就不会 “没头没
脑乱算”,而是有之前的信息打底,迭代过程会更稳定(不会忽快忽慢、误差突然跳变),这就是 “平滑整个滤波器迭代过程” 的意思。
但图优化不一样,它通常没有这种 “对所有状态变量的提前参考(先验)”。所以对图优化来说,怎么处理这份 “提前参考”(比如要不要加、加多少权重),就成了
算法能不能做好的关键问题。
速度观测量
在GINS系统中,如果长时间缺少RTK观测数据,ESKF就变为纯靠IMU积分的递推模式。该模式下位移将很快发散。位移的发散主要原因是缺少速度观测。有没
有什么方法可以限制速度的发散呢?最常见的方法是融入车辆的速度传感器。速度测量值主要来自车辆的电机转速或者轮式编码器。大部分轮式机器人会携带一个
编码器以测定自身速度,进而推断自身的局部运动情况。有时候我们也可以使用电机转速、油门等底层测量值来测定机器人的速度值。这些速度观测与IMU结
合,可以形成局部的航迹推算(Dead Reckoning)。
代码实现思路:
代码实现思路
- 读取轮速数据:从编码器或电机转速计获取vwheel(注意坐标系转换,确保与 ESKF 中的速度坐标系一致)。
- 计算速度残差:$residual=v_{wheel}−\tilde v$($\tilde v$是 ESKF 预测的名义速度)。
- 构造H矩阵:按上述结构,仅速度误差对应位置设为单位矩阵。
- 更新 ESKF 状态:调用卡尔曼增益计算、误差状态修正、协方差更新的函数,完成速度观测的融合。
1 | template <typename S> |
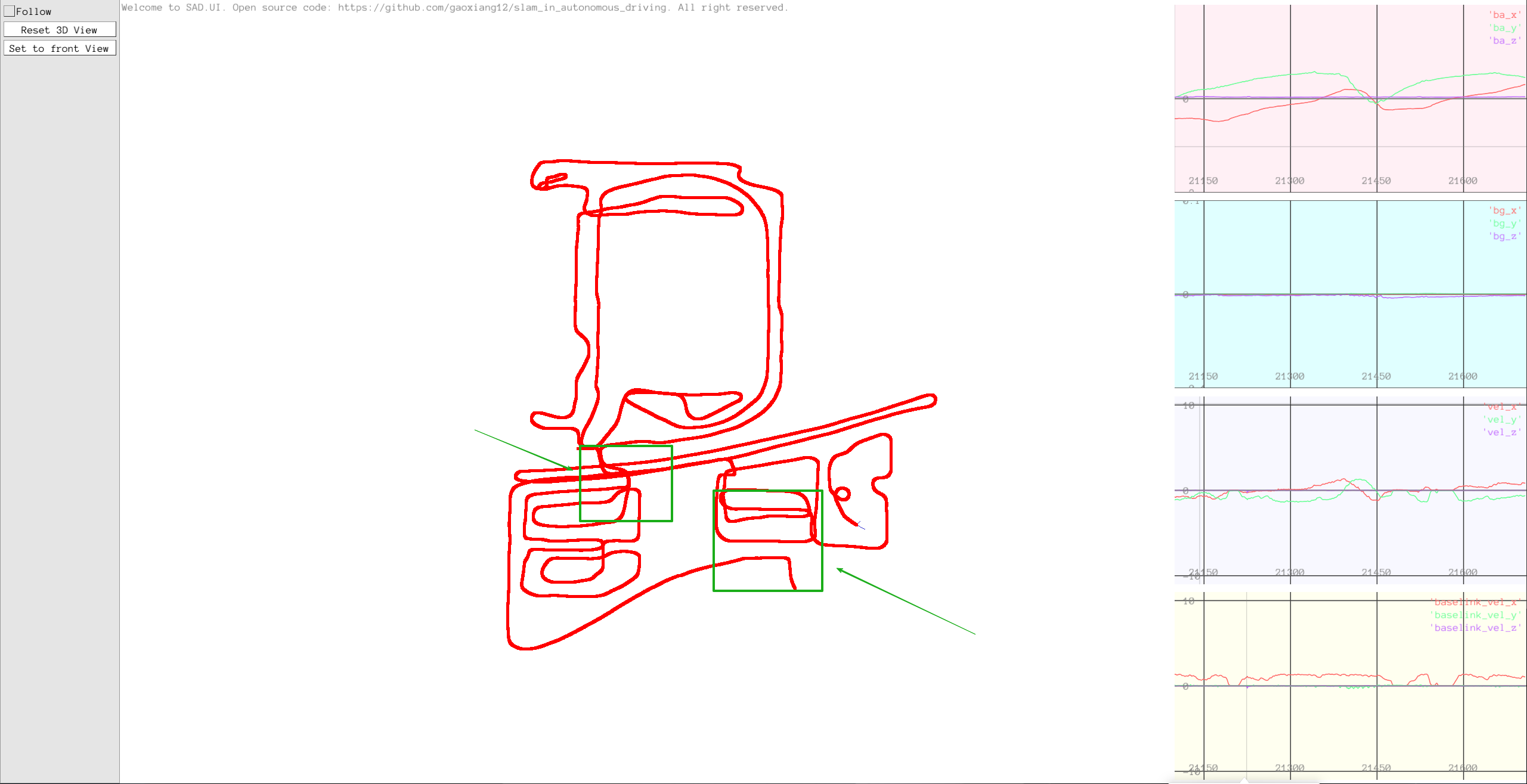
加入轮速里程计后的轨迹图,绿色部分为与上区别,比上面更平滑了。
预积分学
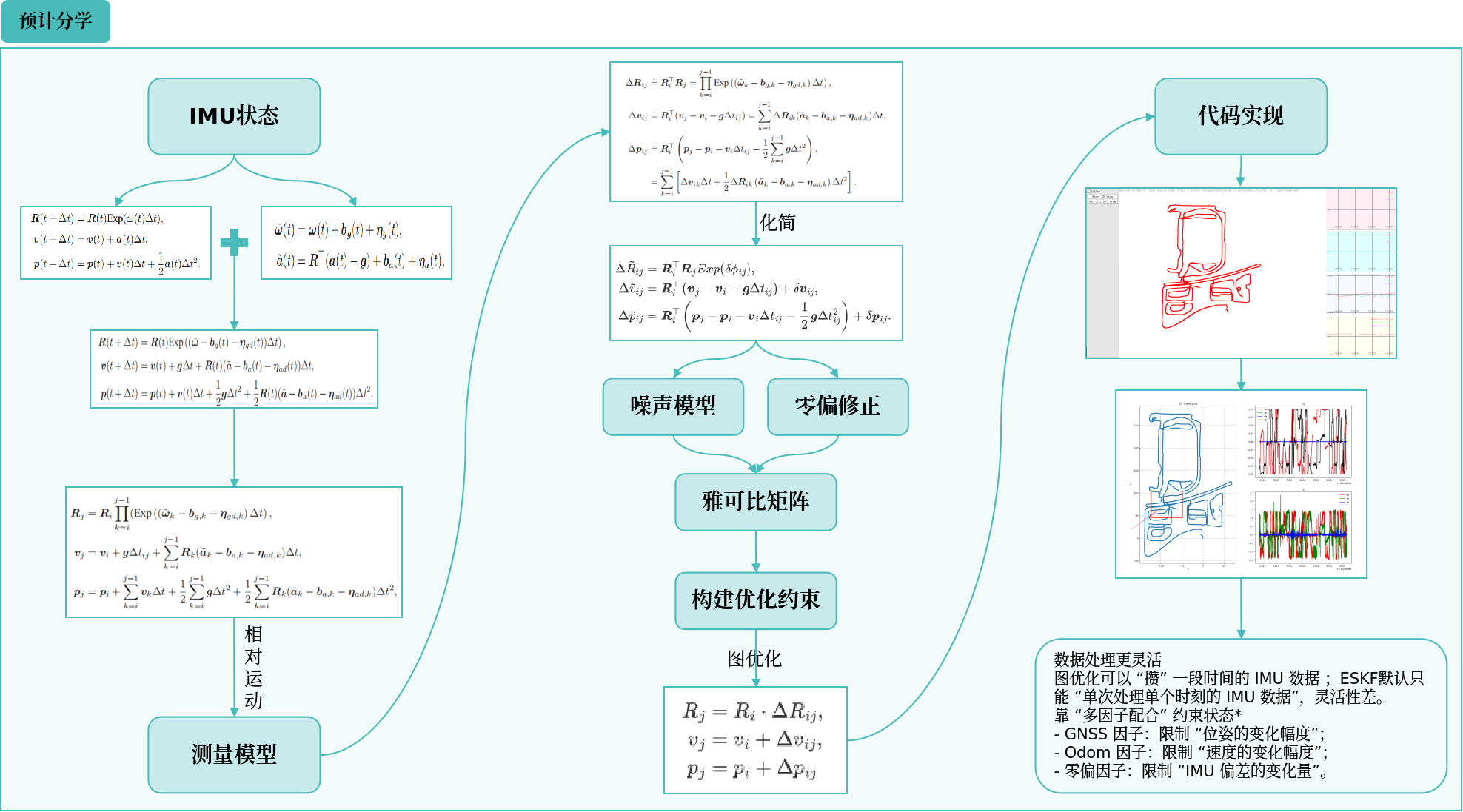
定义
之前的 ESKF(误差状态卡尔曼滤波)处理 IMU 数据时,是 “一次性” 利用:在两个 GNSS(卫星定位)观测的间隔里,把 IMU 数据积分到当前的状态估计上,再
用 GNSS 更新。但这种做法有局限 —— 如果状态估计变了,IMU 数据没法重复用。可从物理角度,IMU 反映的是 “两个时刻间车辆的角度、速度变化量”,理论上
应该能和 “当时的状态估计” 解绑,重复利用。
这就需要 “预积分”:它能把一段时间内的 IMU 测量数据先 “攒起来”,生成一个 “预积分测量值”,而且这个测量值和状态变量无关。打个比方,ESKF 是 “一口
一口吃菜”,预积分是 “先把菜从锅里夹到碗里,再一口气吃碗里的菜”(碗的大小、夹菜次数更灵活)。现在像 LIO(激光惯性里程计)、VIO(视觉惯性里程计)
这类和 IMU 深度结合的系统,预积分已经成了标准方法,只是原理比传统 ESKF 的预测过程更复杂。
IMU频率高100~500HZ,预积分缩短采样频率。
预积分模型可以很容易地与其他图优化模型进行融合,在同一个问题中进行优化。也可以很方便地设置积分时间、优化帧数等参数,相比于滤波器方案更加自由。
推导的关系:“相对运动” 与 “IMU 测量 + 零偏” 的数学关联
预积分推导的是 “关键帧 i 到关键帧 j 的相对运动”(旋转差ΔRij、速度差Δvij、位移差Δpij)和“IMU 原始测量(角速度ω~、加速度a~)+ 传感器零偏(陀螺零偏bg、加速度零偏ba)” 之间的关系。
具体来说,通过对 IMU 的运动学模型(角速度→旋转、加速度→速度 / 位移)进行积分和线性化,把 “i 到 j 时刻的 IMU 测量累积” 转化为 “与 i 时刻状态无关的相对量”。例如:
- 旋转差$\Delta \boldsymbol{R}_{ij}$:由角速度测量扣除陀螺零偏后,通过指数映射累积得到;
- 速度差$\Delta \boldsymbol{v}_{ij}$:由加速度测量扣除加速度零偏、重力后,通过旋转矩阵变换并积分得到;
- 位移差$\Delta \boldsymbol{p}_{ij}$:由速度差和加速度的二次积分得到。
测量模型
从离散时间点$i$到$j$这段时间里,把 IMU 收集的所有数据 “攒起来” 处理,这个过程能持续好几秒,攒出来的结果就叫预积分。不过,如果用的运动学模型不同,预
积分的形式也会不一样。直接积分 IMU 数据有个缺点:积分过程和 “状态量”(比如某时刻的位置、速度)绑得太死。要是优化了$i$时刻的状态,$i-1$、直到$j−1$
时刻的状态都得跟着变,积分就得重新算,特别麻烦。所以得改造一下,尽量把 IMU 读数和状态量分开,于是定义了相对运动量。
使用相对量
旋转、速度、位移如下:
可以转化为
左侧变量的定义方式非常适合程序实现。$\Delta \tilde{R}_{ik}$可以通过 IMU 读数得到,$\Delta \tilde{v}_{ik}$可以由 k时刻 IMU 读数和 $\Delta \tilde{R}_{ik}$算得,而 又$\Delta \tilde{p}_{ik}$可以通过前两者计算结果得到。另
一方面,如果知道了 k 时刻的预积分观测量,又很容易根据 $k + 1$时刻传感器读数,计算出$k + 1$ 时刻的预积分观测量。这是由观测的累加定义方式决定的。
其中$Exp(\delta \phi_{ij})、\delta \boldsymbol{v}_{ij}、\delta \boldsymbol{p}_{ij}$为噪声,下面讨论下其噪声模型。
噪声模型
零偏更新
使用过程
预积分的使用围绕 “预计算 - 构建约束 - 修正零偏” 展开:
1. 预计算
在两个关键帧(如相机 / 激光的关键帧)之间,持续采集 IMU 数据,按预积分公式累积计算$\Delta \boldsymbol{R}_{ij} 、\Delta \boldsymbol{v}_{ij}、\Delta \boldsymbol{p}_{ij}$,并记录积分过程中的噪声和雅克比矩阵(用于后续优化)。
2. 构建优化约束
在图优化(或滤波)中,预积分量作为 “相对运动约束”,把不同关键帧的状态(如$i$帧的$R_i,v_i,p_i$和$j$帧的$R_j,v_j,p_j$)连接起来。例如:
这些约束会被转化为 “优化的代价函数”,让算法在调整关键帧状态时,必须满足 IMU 预积分的相对运动关系。
3. 修正零偏
IMU 的零偏(bg,ba)会随时间漂移,若零偏变化,理论上预积分量需要重算。但预积分通过 “零偏修正公式”,直接调整已有的预积分量(不用重积分 IMU),就
能适配零偏的变化。例如,陀螺零偏变化δbg时,旋转差ΔRij可通过 “指数映射修正项” 调整,避免重复积分。
| 对比项 | ESKF(误差状态卡尔曼滤波) | 基于预积分的图优化 |
|---|---|---|
| 处理逻辑 | 逐帧递推更新(局部) | 全局批处理优化(多帧联合) |
| 误差积累 | 易逐帧累积 | 可全局消除累积误差(如回环) |
| 实时性 | 高(逐帧计算量固定) | 中(计算量随关键帧增加上升) |
| 鲁棒性 | 对异常敏感 | 抗干扰强(多约束 / 核函数抑制) |
| 传感器扩展性 | 弱(添加新传感器需重推导) | 强(易扩展多传感器约束) |
数据处理更灵活
图优化可以 “攒” 一段时间的 IMU 数据 (;而 ESKF默认只能 “单次处理单个时刻的 IMU 数据”,灵活性差。
靠 “多因子配合” 约束状态
预积分是个 “灵活的优化单元(预积分因子)”,能关联位姿、速度、IMU 偏差等多个状态,但自身不稳定,得和其他因子配合:
- GNSS 因子:限制 “位姿的变化幅度”;
- Odom 因子:限制 “速度的变化幅度”;
- 零偏因子:限制 “IMU 偏差的变化量”。
先验因子 让结果更平滑
有个 “先验因子” 能让估计结果更平稳,但严格来说需要复杂处理,这里为了简化用了 “固定参数”。(第 8 章会详细讲它的实现,你可以试试去掉这个因子,看轨迹会不会变得不稳定。)
算力需求高,但实时可用
图优化的计算量比滤波器(如 ESKF)大,更费时间;但现在智能汽车的算力提升了,实时场景下也能顺畅运行。
基础点云处理
查看命令
1 | pcl_viewer ...pcd |

代码查看
1 |
|

将点云转换为俯视图像
1 | // 引入gflags库,用于解析命令行参数 |
最近邻问题
最近邻问题是许多点云问题中最为基本的一个问题,也是众多匹配算法将反复调用的一个步骤。最近邻问题描述起来非常简单:在一个含 n 个点的点云
$X = {x_1,……,x_n}$中,我们会问,离某个点 $x_m$最近的点是哪一个?进一步,离它最近的 k 个点又有哪些?或者与它距离小于某个固定范围 r 的点有哪些?前者
称为 k 近邻查找(kNN),后者称为范围查找(range search)。这个看起来简单的问题处理起来却并不容易,存在众多不同的思路来解决它。我们非常关心最近
邻问题的求解效率,因为这个算法通常成千上万次地被调用,每一次调用增加一点点时间,就可能让匹配算法产生显著的效率差异。下面我们按照由简至难的顺序
地来介绍最近邻方法,这也符合算法技术的实际发展方向。
拟合问题
提取和估计基本元素。这类问题有时也属于 “检测” 或 “聚类”,更偏向感知方法。比如自动驾驶领域,很关心从点云里找出车辆、行人这些有语义的元素,用它们
给后续决策(比如刹车、变道)和路径规划提供数据;但在 SLAM(同时定位与建图)里,更关注用这些元素让不同时刻的点云 “对齐”(配准)。所以传统 SLAM
里,关注的往往是基本、静态的元素,而非动态、带语义的 —— 毕竟让一个点和一个平面对齐容易,让两辆车的点云对齐,得做很多额外工作。
同样一个线性拟合问题,站在不同角度会有不同的提法。有时它被称为线性回归(Linear regression)(对直线的参数进行回归),有时也被称为主成分分析(Principal component analysis, PCA)(对点云的主要分布轴进行分析)。
2D SLAM
基本原理
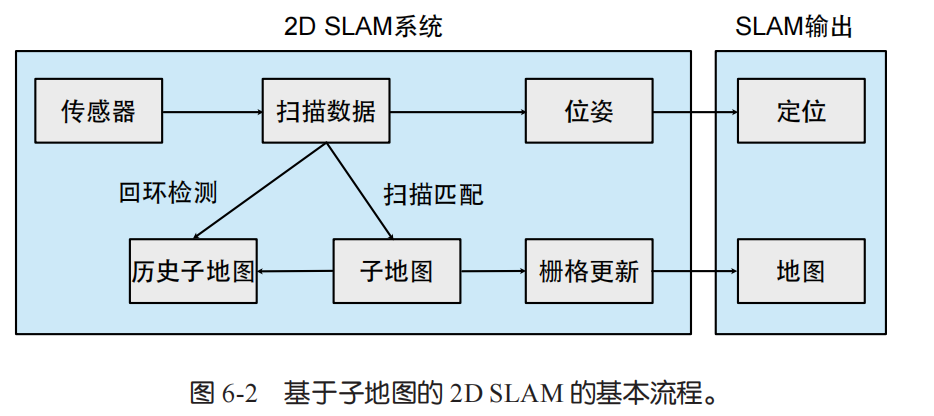
- 激光扫描的基本单位:2D 激光传感器会一圈一圈地往外测距离,每一圈的所有数据合起来叫一次 “扫描(scan)”。
- 怎么确定机器人位置(扫描匹配):要知道这次扫描时机器人在哪儿、朝向哪(位姿),得用 “扫描匹配” 算法 —— 要么把当前扫描和上一次的扫描对比(叫 scan to scan),要么和已有的地图对比(叫 scan to map),原理差不多,实际能用得很灵活。
- 地图的管理方式(子地图模式):扫描的位姿估计好后,得把它放到地图里。如果简单按时间顺序堆所有扫描,误差会越积越多,还容易被移动物体(比如路过的车、人)干扰。现在常用 “子地图”:把相邻的几次扫描打包成一个 “子地图”,再把这些子地图拼起来。子地图内部是固定的,不用重复计算;每个子地图有自己的坐标系,相互之间的位置还能调整优化。处理 “回环”(机器人回到之前去过的地方)时,直接拿子地图当 “积木块” 调整就行,比早期只用一张大地图灵活方便多了。
- 地图的存储与更新:地图得能区分 “哪里能走” 和 “哪里是障碍物”。常用 “占据栅格地图” 来管理,它能把移动物体的干扰过滤掉,让地图更 “干净”(比如路过的车开走后,地图里不会还留着它的痕迹)。
扫描匹配算法
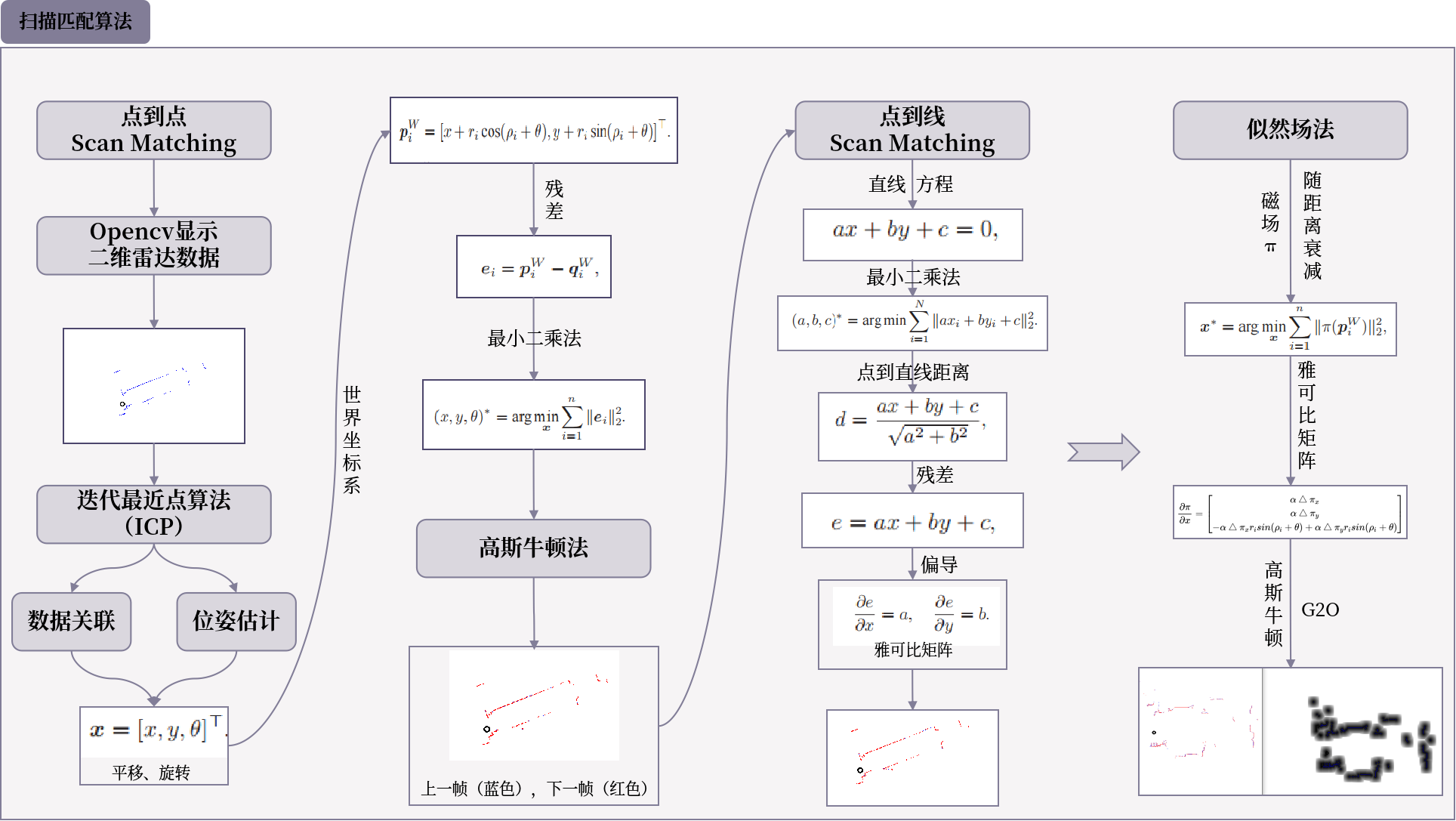
点到点的Scan Matching
使用Opencv显示二维雷达数据
第一句 DEFINE_string(bag_path, "./dataset/...", "数据包路径");
这是使用gflags库定义一个命令行参数:定义了一个名为bag_path的字符串类型参数,gflags会自动生成一个对应的全局变量FLAGS_bag_path(通常位于
fLS命名空间下,即fLS::FLAGS_bag_path),用于存储该参数的值(若运行时通过命令行指定新路径,会覆盖默认值)。
1 |
|
末端点有两层物理含义:(1)末端点本身表示一个实际存在的障碍物;(2)从传感器到末端点的连线上,不存在其他的障碍物。注意第 2 层含义需要计算传感器
到末端点的连线(传感器并不会测量这条连线。它只能测量末端点,所以这条连线的方程需要我们自己计算)。如果我们还想计算这条连线经过哪些栅格,就会涉
及到光线投射算法(ray casting)和栅格化算法(rasterization)。
数学模型
从状态估计的角度来看,2D 激光的扫描数据可以记作观测数据 $z$。它是由机器人在位姿 $x$ 上对某张地图进 $m$行观测之后得到的数据。其中$\omega$为噪声项。
的目的是根据观测到的$z$和$m$来估计$x$。根据贝叶斯估计理论,$x$可以通过最大后验(Maximum of a posterior, MAP)或最大似然(Maximum of likelihood
estimation,MLE)估计得到:
核心是 “怎么让两次激光扫描对上号”
当只考虑 “当前扫描和上一次扫描匹配(scan to scan)” 时,关键是定义观测方程(算出 “预测和实际的差距”,也就是残差)。
如何定义观测方程的详细形式,即为每一个观测数据计算残差项。常见的方法:点到点的 scan matching (迭代最近算法 ICP), 点到线的 scan matching (PL-
ICP,或 ICL),以及高斯似然场法(或 CSM )。
观测方程要解决三个问题
- 选哪些点来匹配:理论上所有激光扫到的点都该参与,但为了速度快,会 “采样”(比如均匀选点、随机选点,或者按点的法线、特征来选)。
- 扫描点对应地图哪个点:通常用 “最近邻” 法 —— 假设当前估计的位置附近,地图里最近的点就是匹配点;也可以从地图的栅格或 “场” 里找最近的点。
- 怎么算差距(残差):激光本身的噪声模型很复杂,实际常用简化版,比如直接当成 “二维高斯分布”(误差像正态分布那样,均值为 0,方差用 Σ 表示)。
点到点的ICP 算法
把 “扫描匹配” 拆成两步:数据关联(找扫描点和地图点的对应关系)+ 位姿估计(算机器人的位置和朝向),然后交替做这两步,直到结果稳定。只要算法是 “交
替这两步”,都算 “类 ICP” 算法。如果提前知道匹配关系,ICP 能直接解方程,但这样会少了 “过滤错误点(异常点)” 的机会,不过从优化角度看,点到点、点到
面的方法其实是相通的。这里就用 “残差 + 优化” 的形式来讲解这些算法。
用高斯牛顿法来实现 “二维点云对齐(ICP)”。每次迭代时,要做两件核心事:
- 找 “最近的点对”(比如把新扫描的点,和地图里已有的点一一对应起来,找距离最近的那个)K-d数查找;
- 用高斯牛顿的方法,根据这些最近点对,算出 “机器人位姿(位置 + 朝向)该怎么微调”,反复迭代,直到点云对齐得足够好。
高斯牛顿迭代函数
1 | // 函数功能:使用高斯牛顿法实现2D ICP(迭代最近点)算法,对齐源激光扫描和目标点云,优化位姿 |
实现
1 | // 引入gflags库,用于解析命令行参数 |
似然场
- ICP 方法的局限
点到点 / 点到线的 ICP(迭代最近点)能让激光扫描之间对齐,也能和地图对齐。但二维 SLAM 里,地图常存成占据栅格地图(像网格拼图,还能过滤动态物体,
比如开走的车)。这时 ICP 每次迭代都要重新找 “最近点对”(像给点装 “弹簧” 拉对齐),效率不高。
2. 似然场法的 “聪明思路”
把点云想象成有 “吸引力场”:
- 不像 ICP 那样 “点对点装弹簧”,而是让点云周围形成一个 “场”,附近的点会被这个场吸引,距离越远,吸引力衰减得越快(比如按距离平方或高斯规律减弱)。
- 激光测到的点落在这个场附近时,用场的 “强弱” 来算误差,不用每次都重新配对点,更高效。
- 似然场的应用
它既能让两次扫描对齐,也能让扫描和地图(尤其是栅格地图)对齐。生成时,会在每个点周围 “画” 一个随距离变淡的圆圈(提前做好,固定不变);后续栅格地
图也能生成自己的似然场,还能和 “子地图” 结合,实现快速对齐。
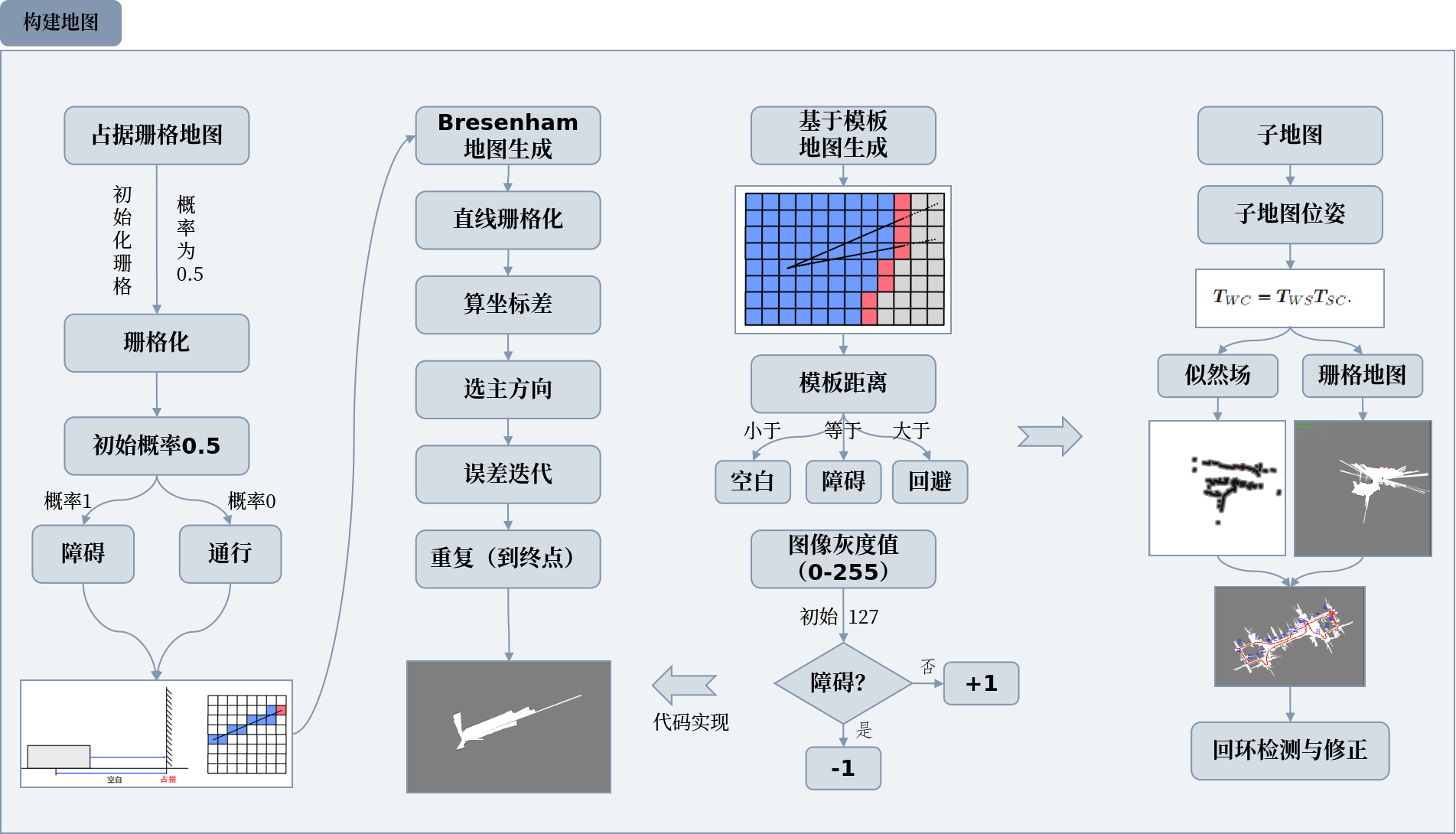
珊格地图
SLAM(同时定位与建图)里,“扫描匹配” 能确定激光扫描和地图的相对位置后,就要考虑 “怎么建图”。早期直接建一整张图有局限,现在常用更灵活的栅格地图 + 子地图模式。
占据栅格地图是啥
把地图分成很多小方格(栅格),每个方格存 “有没有障碍物” 的概率。它形式简单、灵活:既可以存 “这里有没有障碍”(用于机器人找路),也能存 “语义信息”(比如区分是车还是人);而且和图像关联紧密,用 OpenCV 这类图像库就能存和显示。
怎么用激光更新栅格概率
- 初始时,每个栅格 “有障碍” 的概率设为 0.5(因为不知道有没有)。
- 激光多次扫到某个栅格有物体,它的 “有障碍概率” 会慢慢升到 1;多次扫到能通行,概率降到 0。
- 2D 激光的特点:激光打到的 “末端点” 所在栅格是 “被占据(有障碍)”,激光从车身到末端点的连线经过的栅格是 “可通行”—— 所以能靠激光数据,方便地更新每个栅格的 “占据情况”。
两种栅格的区别
- 占据栅格:概率 1 = 有障碍物。
- 通行栅格:概率 0 = 能通行。
两者只是 “概率含义相反”,本质都能表示地图,实际用的时候可以自由选。
栅格地图里的每个小格子,存的是 “这个格子被障碍物占了的概率”(不是非黑即白说 “有” 或 “没有”)。比如:
- 反复观测到某个格子有障碍,概率会慢慢升高;
- 要是格子先有物体、后来物体又移走了,概率会先升、之后再下降
二维激光发射后,激光打到的终点格子,判定为 “有障碍(占据)”;从激光传感器到终点的路径上的格子,判定为 “空白(没障碍)”。
但这招只适合 “完全平的二维场景”:如果机器人有高度(比如要爬台阶),或者激光发射角度歪了,就不准了 —— 因为二维激光测不到 “高度方向的障碍”(比如台阶、桌子这类,会挡路,但二维栅格地图看不出来)。
把连续的激光线条,转换成每个格子的 “概率增减”,这个过程叫栅格化。如果激光角度特别细、测距特别远,栅格化会很慢。所以有两种做法:
- 对每条激光线单独做栅格化;
- 提前算一个 “固定大小的模板区域”,再对模板里的点做栅格化。
后面会实现这两种方法,对比谁更快、更好用。
基于模板的地图生成
栅格填充的 “模板技巧”
如果激光测距很远(比如 100 - 200 米),或者不想用复杂的直线填充算法,就用模板法:提前做一个 “模板区域”,里面每个小格子的角度、距离都是预先算好的。更新地图时,把模板里的格子距离和激光实际测得的距离对比:
- 模板格子距离 比激光测得的近——这个格子是 “空白”(没障碍);
- 模板格子距离 和激光测得的一样 —— 这个格子 “被占据”(有障碍);
- 模板格子距离 比激光测得的远—— 不管这个格子。
这样就不用给每条激光线单独做 “栅格化”,更省事。
概率更新的 “偷懒方法”
理论上,栅格该存 “0 - 1 之间的占据概率”,但计算要用到对数、指数,很麻烦。工程上直接用 图像灰度值(0 - 255) 代替:
- 灰度值 127—— 这个格子 “未知”(没测过);
- 每次检测到障碍—— 灰度值减 1;
- 没检测到障碍—— 灰度值加 1;
- 同时限制灰度值的最大、最小计数(比如不低于 0、不高于 255)。
这样既统计了 “看到障碍的次数”,又省了复杂计算。
实现时的几个要点
后面要用 “子地图” 管理地图和回环检测,所以:
- 每个子地图都生成自己的占据栅格地图,用子地图的坐标系(没做回环修正时,就是地图坐标系);
- 占据栅格地图会和之前讲的 “似然场” 结合,且用栅格里已经标为 “障碍” 的部分来生成似然场;
- 先讲怎么用二维激光扫描生成局部栅格地图,下一节再讲多个栅格地图如何合并成全局地图。
代码里最核心的是 “栅格化算法”:知道激光扫描的位姿后,用模板法判断哪些格子是障碍、哪些能通行。
子地图
原理
子地图是 “中间打包层”:把多个匹配好的激光扫描数据,组合成一个个 “子地图”。它比单个扫描大、比全局地图小,不管 2D 还是 3D 激光 SLAM,用起来都
灵活。
子地图的位姿能单独调:每个子地图有自己的 “位置 + 朝向”(用$T_{WS}$表示,描述子地图在世界坐标系里的状态)。当新激光扫描(记为C)来匹配时,先算 “扫描
相对于子地图的位置关系”($T_{SC}$)。那扫描在世界里的最终位置,就是 “子地图在世界的位置” 乘 “扫描相对于子地图的位置”。
修图更方便:这种做法的好处是,要是后期发现地图整体有偏差(比如回环检测到重复区域),不用修改子地图内部每个扫描的相对位置,只需要调整每个子地图
自己的$T_{WS}$就行。回环检测时,把每个子地图当一个 “小积木” 来处理,不用纠结每个激光帧的细节,效率更高。
实现步骤
- 每个子地图都配套 “似然场”(辅助匹配的工具)和 “栅格地图”(存地图的网格)。
- 每次新的激光扫描数据,都和当前子地图匹配,算出扫描在这个子地图里的 “位置 + 朝向(位姿)”。
- 机器人移动 / 转动到一定距离、角度时,选一个 “关键帧”(把此时的扫描当成重要节点)。
- 若机器人超出当前子地图范围,或子地图里的关键帧太多,就新建子地图:新子地图以当前扫描为中心,它在世界中的位姿设为$T_{WS} =T_{WC}$;新地图初始没数据,为了后续好匹配,把旧子地图里最近的关键帧复制过来。
- 把所有子地图的栅格地图 “拼起来”,就得到全局地图。
| 变量名 | 类型 | 说明 |
|---|---|---|
pose_ |
SE2 |
子地图在世界坐标系中的位姿(Tws),SE2表示二维位姿(包含 x、y 平移和旋转角) |
id_ |
size_t |
子地图的唯一标识 ID,默认 0 |
frames_ |
std::vector<std::shared_ptr<Frame>> |
存储属于该子地图的所有关键帧(Frame为传感器帧数据结构) |
field_ |
LikelihoodField |
似然场(一种概率地图,用于快速匹配传感器数据与地图) |
occu_map_ |
OccupancyMap |
占据栅格地图(用栅格表示环境中 “占据” 或 “空闲” 的区域) |
1 | /** |



回环检测与闭环
1.选哪些历史地图来检测?
得找出和当前扫描位置可能重叠的旧地图。但如果之前攒的误差太大,估计的轨迹不准,就可能选错该匹配的地图,导致回环没检测对。所以得对 “误差大概有多大” 有个基本判断,才能选对检测对象。
2. 回环的匹配方法,和里程计里的不一样
里程计是 “连续运动” 的,默认初始位姿和最终最优结果差别不大。但回环时,因为误差累计,初始估计的位姿可能差得很远。这时候原来的 ICP(迭代最近点)、似然场这些方法就不好使了,得用能处理 “初始位姿差很多” 的方法,比如网格搜索、粒子滤波、分枝定界、图像金字塔这些,它们能在大误差下找到正确匹配。
3. 回环后,怎么修正地图?
检测到回环,就得调整整个地图的位姿。可以基于关键帧的位姿来优化,也可以基于子地图:子地图数量少,用它优化更省事,但子地图优化没法修复 “单个子地图内部的变形”,所以有些系统还是得用关键帧作为基本单元来优化。
多分辨率回环检测
金字塔式回环检测(也叫 “由粗到精”“多分辨率配准”),核心是一种 “先粗略对齐,再精细调整” 的思路 —— 不光用于点云匹配,在计算机视觉(比如光流法)、数学规划(比如分枝定界法)里也很常用,目的是快速找最优解,还不影响效果。
具体到 “多分辨率似然场匹配”(属于扫描匹配,解决 “初始位姿估计不准” 的问题):
因为初始位姿误差大时,激光点容易出现大偏差,甚至被误判为 “异常值” 删掉。所以我们做多个 “清晰度不同” 的似然场(比如低分辨率、高分辨率):
- 低分辨率似然场像 “打了马赛克的地图”,障碍形状模糊、范围大,但误差也小,能先在这层 “粗略对齐”;
- 对齐后,再把结果放到 高分辨率的 “清晰版地图”里,做精细匹配。
比如文中例子用了四层似然场,每层尺寸减半:最底层(小分辨率)连障碍形状都看不清,但能包容更大的初始位姿误差,先在这层 “粗配准”,再往上一层一层细化,就能解决初始位姿不准的问题。
基于子地图的回环修正
当回环检测成功找到 “当前帧与历史子地图的匹配关系” 后,就会启动回环修正,这个过程可以用 “位姿图(pose graph)” 来建模优化 —— 由于之前构建了子地图,优化时只需调整子地图的位姿,不用再管单个激光帧,很高效。
步骤 1:推导子地图间的相对位姿
假设:
- 历史子地图S1在 “世界坐标系” 中的位姿是$T_{WS_1}$;
- 当前帧的位姿是TWC;
- 当前子地图S2在 “世界坐标系” 中的位姿是$T_{WS_2}$。
通过 “多分辨率匹配”,能算出当前帧相对于历史子地图S1的位姿TS1C。接着,就能推导出自历史子地图S1和当前子地图S2之间的相对位姿TS1S2(用公式计算),这样就明确了两个子地图的 “对齐关系”。
步骤 2:位姿图优化(调整子地图位姿)
把每个子地图的位姿作为 “优化变量”,构建 “位姿图”。位姿图的 “约束” 来自两方面:
- 相邻子地图之间的相对位姿观测(比如相邻子地图天然的位置关联);
- 回环检测算出的子地图间相对位姿(比如S1和S2通过回环得到的关系)。
以子地图1和2为例:假设回环检测算出它们的相对位姿是$T_{S_1S_2}$,那么 “误差残差e” 就是用这个观测值,对比子地图实际位姿(TWS1、TWS2)算出来的(公式。
这里计算误差的 “雅可比矩阵”(描述变量变化对误差的影响)比较复杂,通常让程序自动求导即可。
步骤 3:防止错误回环
为了避免 “误判的回环”(把不是回环的情况当成回环),还要验证:修正后的累计误差不能太大,否则就把这个 “假回环” 当成 “异常值” 删掉,不参与优化。
简单说:回环修正靠 “位姿图优化子地图位姿”,约束来自 “相邻关系” 和 “回环检测结果”,同时还要过滤 “错误回环”。
3D SLAM

多线激光的Scan Matching
多线激光的扫描匹配效果通常好于单线激光,所以后端的处理要更加简单,大多数多线激光的 SLAM 系统都不使用子地图这样的概念,而是直
接管理点云本身。于是,点云的配准也主要以 scan to scan 或 scan to map 为主。
点云数量不一样时,ICP(迭代最近点)能实现配准,核心在于通过 “最近邻搜索” 动态建立点对关系,而不是依赖 “初始点数量相同、顺序对应”:
- 动态找 “最近邻” 来配对
对于点云S1中的每一个点pi,都去点云S2中找距离它最近的点qj,把(pi,qj)作为 “匹配点对”。
- 哪怕S1和S2的总点数不同(比如S1有 100 个点,S2有 200 个点),也能为S1的每个点找到 “最近邻居”;
- S2里的点可能被多个S1的点选为 “最近邻”,也可能有些点没被选中 —— 但这不影响,因为我们只需要 “当前迭代下,尽可能近的点对” 来计算变换。
- 用点对求变换,迭代优化
有了这些 “最近邻点对” 后,就可以用最小二乘法等方法,求解让pi≈Rqj+t(旋转R、平移t)误差最小的变换。
然后,用这个变换调整其中一个点云(比如把S2按R,t变换),再重复 “找最近邻→求变换” 的过程,直到点云对齐得足够好(误差足够小或迭代次数足够)。
举个例子:比如S1是物体 “正面扫描的 100 个点”,S2是 “侧面扫描的 200 个点”。ICP 会为S1的每个点,在S2里找最近的点(可能是侧面上的点),然后通过这些点对算 “旋转 + 平移”,把S2往S1的方向对齐;调整后再重新找最近邻,反复迭代,直到两个点云整体重合。
简言之:ICP 不要求点云 “点数相同、顺序对应”,而是靠 “动态找最近邻” 来建立临时点对,进而逐步优化配准。
NDT方法
NDT(正态分布变换)是一种点云配准方法,核心是用 “统计信息(均值、方差)” 代替 “单个点” 来做匹配,步骤通俗易懂的解释如下:
1.把目标点云 “切块”
先把要配准到的目标点云,按固定分辨率分成很多小 “体素”(类似把蛋糕切成小块)。
2.统计每个 “小块” 的分布
每个体素里的点,会符合 “高斯分布”(可以理解为 “点的聚集规律”)。计算每个体素的均值(点的平均位置,记为μk)和方差(点的分散程度,记为Σk)。
3.让待配准的点 “贴合统计规律”
拿要配准的点云里的点$q_i$,用当前估计的 “旋转R + 平移t” 变换后,看它落到哪个体素里。然后用这个体素的均值μi,算 “残差”:$e_i=Rq_i+t−μ_i$(残差是 “变换后点的位置” 和 “体素均值” 的差距)。
4. 优化旋转和平移,让残差最小
通过高斯 - 牛顿(G-N)或列文伯格 - 马夸尔特(L-M)方法,最小化 “残差的加权和”(权重由体素方差的逆$Σi^{−1}$决定),找到最优的R和t。这相当于让变换后的点,尽可能符合目标体素的 “分布规律”,也就是最大化点落在对应体素里的概率(专业说法叫 “最大似然估计”)。
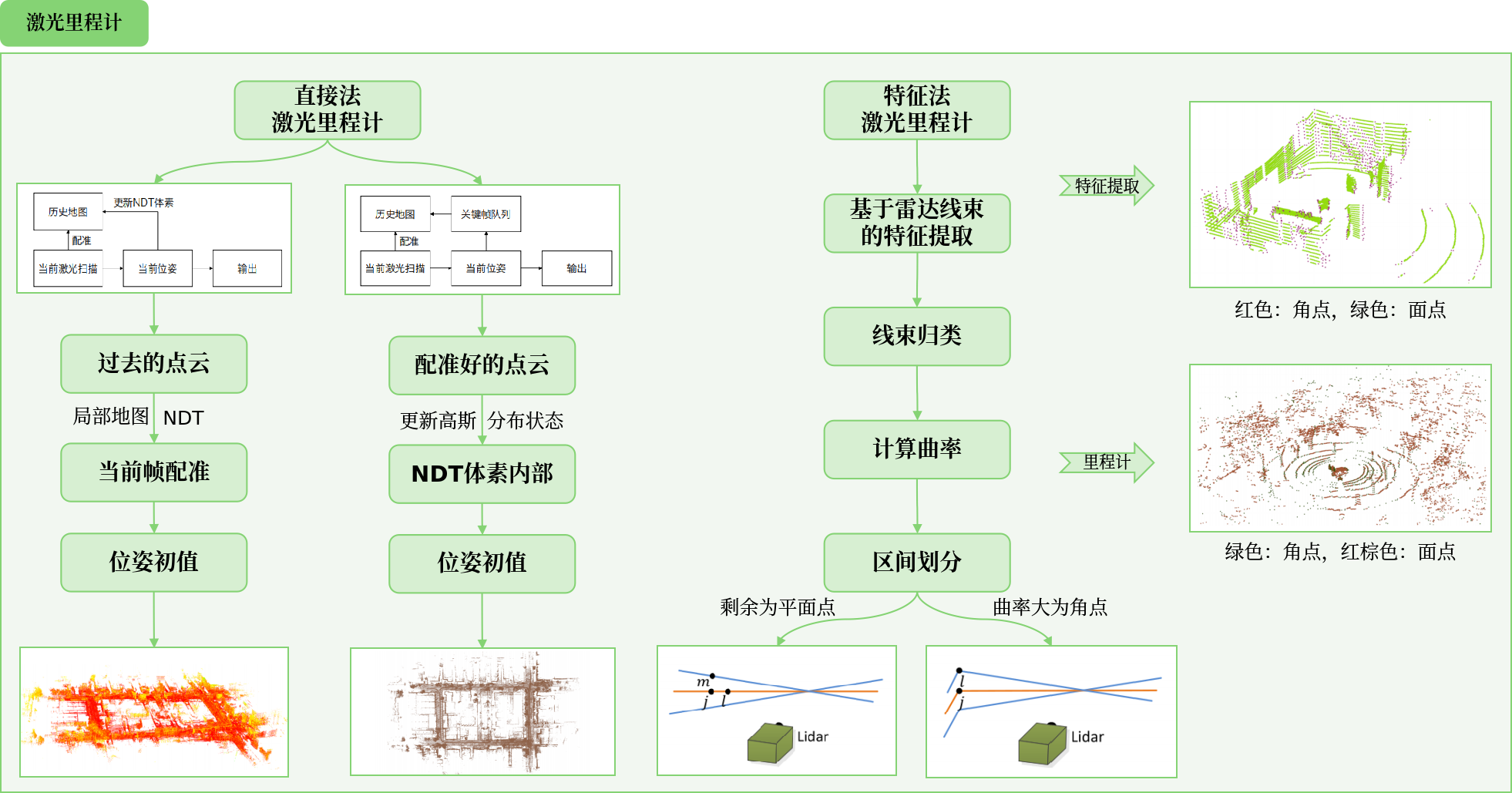
直接法的激光里程计
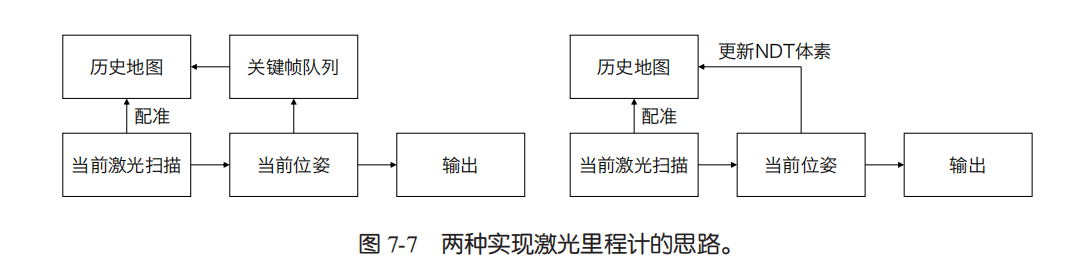
- 直接法激光里程计:要么 “当前激光扫描和上一次的扫描直接对齐”;要么在 3D 场景下,把最近一段时间的点云凑成一个 “小局部地图”,再让当前新扫描的点云和这个小地图对齐。这种方法不用特意找 “点云里的特殊特征(比如尖角、平面)”,直接拿整点点云来匹配,还能基于 ICP 或 NDT 实现(看左侧流程图)。
- 增量式 NDT:想更高效的话,不用每次都重新拼 “小局部地图”。而是把已经匹配好的点云,直接更新到 NDT 的 “小方块(体素)” 里,同时更新每个小方块内点的 “分布规律(比如点集中在哪里、分散程度如何)”。之后新的点云来匹配时,直接用这些更新好的小方块信息,不用反复建复杂的查找结构(比如 Kd 树这类帮快速找东西的索引),速度更快。接下来会实际做这两种 NDT,比比谁的计算效率更高。
特征法的激光里程计
简单来说,用 “特征法” 做激光雷达的 SLAM(定位 + 建图)时,要搞清楚两件事:多线激光雷达该提取什么样的 “特殊点(特征)”,以及怎么用这些特殊点让不同帧的点云对齐。
虽然点云特征有很多种(比如 PFH、FPFH,还有深度学习搞出来的),但实时 SLAM 里对特征有几个实用要求:
- 特征得匹配激光点云的特点 —— 自动驾驶的激光点云是 “一束一束的线”(不像 RGB-D 相机点云那么密),所以不用对整个点云提取特征,针对每一条激光线上的点提取就行。
- 提取特征后,得能轻松用这些点做几何对齐(比如用之前讲的 ICP、NDT 这些方法)。
- 提取特征不能太费电脑资源(CPU/GPU 别过载),也别依赖特殊硬件(否则不好普及)。
- 整个系统(激光里程计或 SLAM)的计算要统一,别一部分在 CPU 跑、一部分在 GPU 跑,避免数据传来传去浪费资源。
大部分系统会使用线束信息来进行特征提取。下面我们介绍类 LOAM 系统的特征提取方法。
多线激光雷达的点云自带 “线束” 相关信息,利用这些信息能提取有用特征,通俗解释如下:
激光点的 “额外信息” 很有用
从多线激光雷达得到的点,除了位置(x,y,z),还能知道:
- 这个点来自哪条激光扫描线;
- 同一条扫描线上,点的先后顺序;
- 甚至能拿到极坐标角度、扫描时间等精细信息。
这些信息能帮上大忙:比如不用费力去找 “同一条线上点的最近邻居”;还能通过 “曲率”(同一条线上,一个点和周围点的偏离程度)判断点的类型。
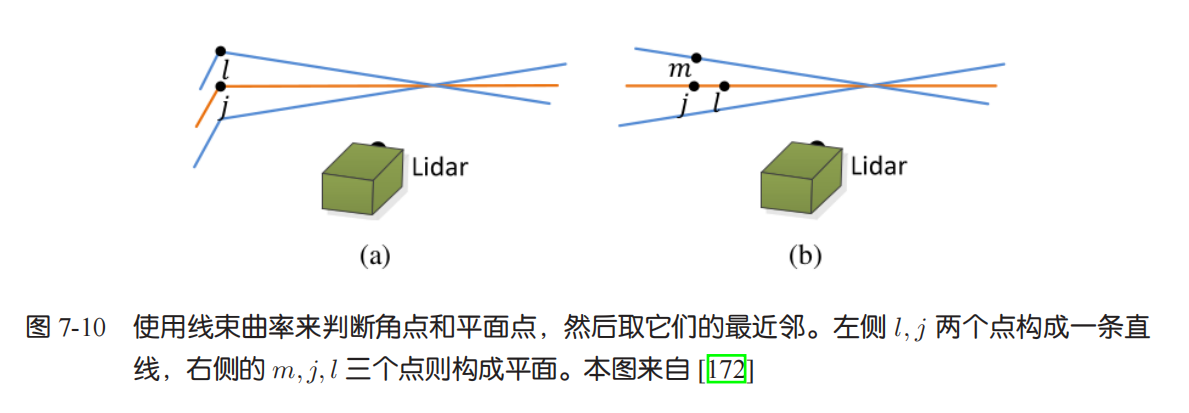
用 “曲率” 挑 “角点 / 平面点”
- 若曲率大(点和周围点偏离多),说明是角点(比如垂直物体表面、两个平面的交界点);
- 若曲率小(点和周围点偏离少),说明是平面点(比如大平面上的点)。
像 LOAM 系列算法,就靠这招挑特征点:角点适合用 “点到线” 的 ICP 配准,平面点适合用 “点到面” 的 ICP 配准(如图,左侧两点成直线对应角点,右侧三点成平面对应平面点)。
适用范围与局限性
- 这种思路也能用于2D 激光雷达;还有其他提取方法,比如 LGoLOAM 用 “距离图像” 提地面点、角点,mulls 用 PCA(主成分分析)提地面、立面等。
- 但这类方法很 “工程化”—— 依赖雷达的 “先天信息”(比如有多少条扫描线、激光是否水平放置),不同雷达得针对性调整。
- 而且,RGB-D 相机的点云没有激光 “线束” 这类信息,所以这类方法在 RGB-D 场景下用不了,限制了使用范围。
特征提取的算法主要包括几个部分:
计算每个点的线束并归类。由于我们在点云中已携带了这部分信息,这步可以跳过。
依次计算线束中每个点的曲率。
把点云按一周分成若干个区间(实现当中取 6 个区间)。选择其中曲率最大的若干个点作
为角点。剩余的点作为平面点。
松耦合LIO系统
松耦合 LIO(激光雷达 - 惯性里程计)系统,是激光雷达与 IMU(惯性测量单元)“间接配合” 的定位方式,核心逻辑是 “各算各的结果,再融合”,通俗解释如下:
分工计算
- IMU(结合轮速)负责提供 “惯性层面的运动趋势”:比如 IMU 测量角速度、加速度,反映机器人运动的 “动态变化(比如加速、转弯)”;
- 激光雷达负责通过点云匹配(如 ICP、NDT 等方法),算出 “位姿变化的最终结果”(机器人走了多远、转了多少角度)。
融合逻辑:“结果级融合”,而非 “细节级融合”
系统有个 “状态估计器”(比如卡尔曼滤波器),用来综合判断机器人的位置、姿态。松耦合的特点是:不把点云匹配时的 “细节误差”(比如点和线、点和面的匹配误差)直接塞进估计器,而是把激光雷达 “点云匹配好的最终位姿结论” 交给估计器。
这样一来,激光的 “点云匹配部分” 和估计器的 “卡尔曼滤波部分” 是相对独立的(解耦的),实现起来更简单。
双向互助,但有局限
- 点云匹配时,能拿 “状态估计器预测的位姿” 当 “初始猜测”,让点云更快对齐;
- 但如果激光点云的环境很差(比如全是平地,没明显特征),点云匹配会不准,反过来也会影响 “状态估计器” 的准确性。
对比与实现:简单易上手
和 “紧耦合”(把点云匹配的细节误差直接融入滤波,更复杂)相比,松耦合结构简单,适合学习。文中用 “第 3 章的 ESKF(一种卡尔曼滤波) + 增量 NDT(激光点云匹配方法)” 来实现,你也可以把激光匹配换成 ICP 或 “基于特征的方法”。
紧耦合LIO系统
原理
松耦合:“各干各的,只交结果”
每个传感器像 “独立工作的人”,自己把任务做完,只把最终结果交给系统汇总。比如激光雷达自己算 “机器人走了多远、转了多少”,IMU 自己算 “运动的加速度、角速度趋势”,最后系统把这两个结果 “拼起来”。
如果其中一个人(比如激光雷达遇到全是平地,没东西可测)“工作失误”,系统得先 “发现他失误了”,才能想办法补救。
紧耦合:“互相看细节,实时帮忙”
不只是要 “最终结果”,还要看工作过程中的细节。比如关注 IMU 测量时的 “小误差(零偏)”“噪声”,或者激光雷达点云匹配时的 “误差细节”。把这些 “精细信息” 都整合到系统里,相当于团队成员之间 “实时看对方的工作细节,互相纠正”。
紧耦合的好处:“一个不行, others 能兜底”
如果某个传感器(比如激光雷达遇到没特征的场景,快算错了)状态不好,紧耦合因为能拿到 “细节”,其他传感器(比如 IMU)能实时约束它,不让它乱算;反过来 IMU 自己容易 “漂移(误差越攒越多)”,激光的细节也能拉着 IMU 别跑偏。
而松耦合下,一个传感器失效了,系统得先 “识别出失效” 才能处理;紧耦合是 “从根上(细节里)就互相约束”,就算一个传感器状态差,其他传感器能靠细节把它 “拽回正轨”,系统整体更稳定。
基于IEKF的LIO系统
IEKF(迭代扩展卡尔曼滤波器)在紧耦合 LIO(激光雷达 - 惯性里程计)系统里,是用来融合激光雷达和 IMU 数据,精准估计机器人状态的工具,核心逻辑通俗拆解如下:
估计的 “核心状态”(状态变量)
把机器人的关键状态打包成一个集合,定义一个高维流行空间$\mathcal{M}$包括:
按照陀螺仪和加速度计的读数,离散时间对状态进行递推。
IMU 如何 “推算” 状态变化(运动方程)
IMU 会实时测角速度(转多快)和加速度(跑多快)。从当前时刻t到下一时刻t+Δt,机器人的状态会这样更新:
误差的 “传播”(不确定性管理)
IMU 测量有 “噪声”(不准的成分),所以每次推算后,状态的 “不确定性”(用 方差P 表示)会变化。公式里用矩阵F和噪声矩阵Q,算出推算后新的 “不确定性”,为后续和激光数据融合做准备。
激光与 IMU 的 “时间差” 处理
激光雷达的刷新频率比 IMU 低(比如 IMU 每秒测几百次,激光每秒只测几十次)。所以两次激光数据之间,会有很多 IMU 的读数,这时候就用上面的运动方程多次推算,把 IMU 的连续数据都利用起来,得到 “推算后的状态xpred” 和 “不确定性Ppred”,方便后续和激光数据融合。
IEKF
现实中大部分系统都是非线性的(比如雷达测距离:距离 =√(x²+y²),带平方根;卫星定位中速度和位置的关系也不是直线),而普通 KF 只能处理线性系统(比如 “速度 = 加速度 × 时间” 这种 y=ax+b 的关系)。
为了处理非线性系统,人们发明了EKF(扩展卡尔曼滤波):把非线性函数在 “当前估计值” 附近用 “泰勒展开” 掰直(线性化),再用 KF 的逻辑计算。但 EKF 有个致命问题 ——只线性化一次,如果非线性很强(比如曲线很陡),“掰直” 的误差会很大,导致估计不准。
这时候IEKF(迭代卡尔曼滤波) 就登场了:它在 EKF 的基础上,把 “线性化→更新估计” 的过程重复好几次(迭代),每次都用 “最新的估计值” 重新线性化,直到估计值变化很小(收敛),从而减小线性化误差,让结果更准。
习题
CH2
1、

3、




